

"結(jié)構(gòu)就是功能"——蛋白質(zhì)的工作原理和作用取決于其3D形狀。
2020年末,基于深度神經(jīng)網(wǎng)絡的AlphaFold2,一舉破解了困擾生物學界長達五十年之久的“蛋白質(zhì)折疊”難題,改變了科學研究的游戲規(guī)則,可以從蛋白質(zhì)序列直接預測蛋白質(zhì)結(jié)構(gòu),實現(xiàn)了計算機蛋白質(zhì)建模極高的精確度。
自AF2問世以來,全世界數(shù)百萬研究者已經(jīng)在瘧疾疫苗、癌癥治療和酶設計等諸多領(lǐng)域取得了突破。
2024年5月初,AlphaFold3再登Nature,基于Diffusion(擴散技術(shù))架構(gòu),將技術(shù)延伸到蛋白質(zhì)折疊之外,能以原子級精度準確預測蛋白質(zhì)、DNA、RNA、配體等生命分子的結(jié)構(gòu)及相互作用。
為了避免Diffusion技術(shù)在一些無結(jié)構(gòu)區(qū)域產(chǎn)生“幻覺”,DeepMind還創(chuàng)新了一種交叉蒸餾(cross-distillation)方法,把AF2預測的結(jié)構(gòu)數(shù)據(jù)預添加到AF3的預訓練集中,減少AF3的預測失誤。
AF2代碼已開源,AF3目測不會開源,也不能商用。
我們今天的主角——只能是AlphaFold2。
想知道怎么使用AlphaFold2最最快樂?
怎么快速完成蛋白質(zhì)結(jié)構(gòu)預測任務?
我們能在背后幫你默默干點什么?
來吧——
01
先復習一下
AlphaFold2計算的正確打開方式
我們通常說的AlphaFold2是指一個利用多個外部開源程序和數(shù)據(jù)庫,通過蛋白質(zhì)序列預測其3D結(jié)構(gòu)的系統(tǒng)。
整個蛋白質(zhì)結(jié)構(gòu)預測計算過程大致可以分為兩個階段:
一、數(shù)據(jù)預處理
包括多序列比對(MSA)和模板搜索(Template Search)兩個步驟,主要是利用已知的蛋白質(zhì)序列和結(jié)構(gòu)模板,獲得不同蛋白質(zhì)之間的共有進化信息來提升目標蛋白質(zhì)結(jié)構(gòu)預測的準確性。
需要比對和搜索的數(shù)據(jù)總和達到了TB量級,涉及數(shù)據(jù)庫密集I/O讀寫,因此對I/O有較高的要求。
這一階段主要使用HMMER與HH-suite軟件,以及Uniprot、MGnify、PDB等多個蛋白質(zhì)數(shù)據(jù)庫。計算耗時與蛋白序列長度正相關(guān),主要使用CPU計算資源。
AF2訓練數(shù)據(jù)集覆蓋多個數(shù)據(jù)庫,比如UniRef90/MGnify/PDB/BFD等,目前完整版大小約為2.62TB,是世界范圍內(nèi)較為權(quán)威的蛋白質(zhì)三維結(jié)構(gòu)數(shù)據(jù)庫。2022年7月28日,Google DeepMind將數(shù)據(jù)庫從近100萬個結(jié)構(gòu)擴展到超過2億個結(jié)構(gòu),涵蓋了植物、細菌、動物和其他微生物等多個類別。

二 、模型推理與優(yōu)化
基于端到端的Transformer神經(jīng)網(wǎng)絡模型,AF2輸入Templates、MSA序列和pairing信息,其中pairing和MSA信息相互迭代更新,檢測蛋白質(zhì)中氨基酸之間相互作用的模式,輸出基于它們的3D結(jié)構(gòu)。
再用OpenMM軟件對預測的3D結(jié)構(gòu)進行物理放松,解決結(jié)構(gòu)違規(guī)與沖突。
使用Recycling(將輸出重新加入到輸入再重復refinement)進行多輪迭代訓練和測試,多輪迭代優(yōu)化有一定的必要性,較為復雜的蛋白可能在多輪之后才能折疊到正確的結(jié)構(gòu)。
這一階段計算耗時與迭代次數(shù)正相關(guān),主要使用GPU計算資源。
02
Workflow全流程自動化
隨心組合,當一個甩手掌柜
作為一個系統(tǒng),AlphaFold2借助了多個外部開源軟件和數(shù)據(jù)庫,整個計算過程也比較復雜。
如果用戶想要自行使用,不但要下載龐大的數(shù)據(jù)庫,還需要自行搭建使用環(huán)境,對IT能力的要求不可謂不高。
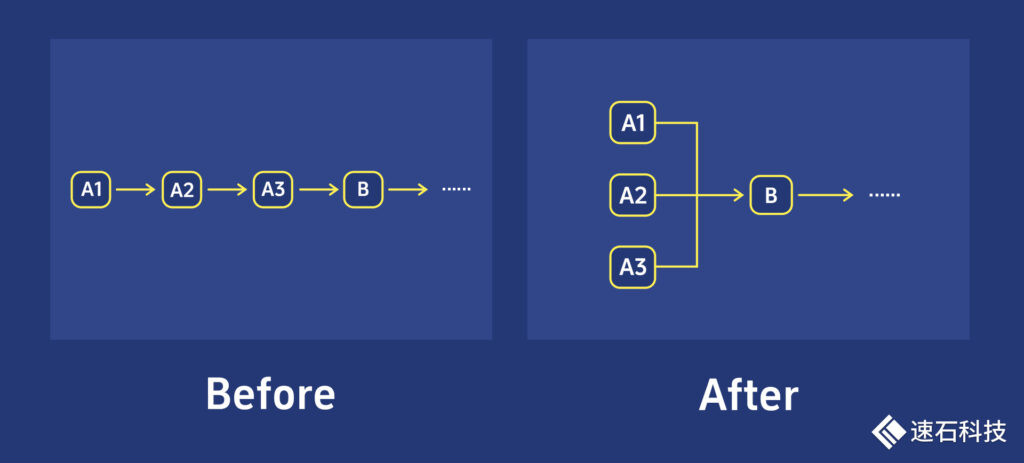
用戶看到的基本都是左邊這種畫面,我們能做的第一點——就是提供一個平臺,把左邊變成右邊:

而第二點,我們能跨越系統(tǒng)各個軟件之間,包括對軟件內(nèi)部的不同步驟任意重新排列組合,做成自動化的Workflow。
一次制作,反復使用,省時省力,還不用擔心中間出錯。
比如?
一 、多數(shù)據(jù)庫同時多序列比對(MSA)
多序列比對需要在多個蛋白質(zhì)數(shù)據(jù)庫里進行查找。
常規(guī)使用模式,用戶要手動依次在N個數(shù)據(jù)庫里進行搜索,整個過程耗時等于N次搜索的時間之和。
我們可以讓不同數(shù)據(jù)庫的搜索同時進行,并做成一個固定Workflow,自動執(zhí)行,整個過程花費時間將等于耗時最長的數(shù)據(jù)庫搜索時間。既節(jié)約時間,又省事。
二 、全計算流程與資源自由組合
不僅僅限于某一個步驟,我們能做全計算流程的自定義Workflow。
上一節(jié)我們復習了,AF2第一階段適合用CPU資源,第二階段使用GPU計算效果最佳,每個階段還涉及到不同軟件包。
整個計算過程比較復雜,需要在不同階段的不同步驟使用不同軟件包調(diào)用不同底層資源進行計算,手動操作工作量不小。而且,常規(guī)使用模式,可能會從頭到尾使用一種資源計算,這樣比較簡單,但是會比較吃虧,要么第一階段GPU純純浪費,要么第二階段慢得吐血,計算時間是原來的數(shù)倍。
我們能把整個計算流程與資源自由組合,讓用戶全程可視化操作,只需要輸入不同參數(shù)即可。既能實現(xiàn)應用與資源的最佳適配,還能自動化操作,省去大量手動時間。

當然,還有無數(shù)種其他組合的可能性。
不止是AlphaFold2,自定義Workflow也能應用在其他場景,戳:1分鐘告訴你用MOE模擬200000個分子要花多少錢
03
掃清技術(shù)障礙
TB級數(shù)據(jù)庫與I/O瓶頸問題
AF2訓練數(shù)據(jù)庫完整版大小約為2.62TB,數(shù)據(jù)預處理階段需要在數(shù)據(jù)庫中執(zhí)行多次隨機搜索,這會導致密集的I/O讀寫。如果數(shù)據(jù)的讀取或?qū)懭胨俣雀簧希蜁绊懙秸麄€計算過程的效率。
這可能會導致:
1. 同一任務多次計算,耗時卻不同;
2. I/O等待超時,任務異常退出;
3. 即便增加CPU資源,也無法加速計算。
為了解決這一問題,我們對整個數(shù)據(jù)庫做了梳理和拆分。其中最大的BFD數(shù)據(jù)庫接近2T,對I/O的要求非常高。
因此,我們將高頻I/O的BFD數(shù)據(jù)庫存放在本地磁盤,其他數(shù)據(jù)庫存放在網(wǎng)絡共享存儲上。
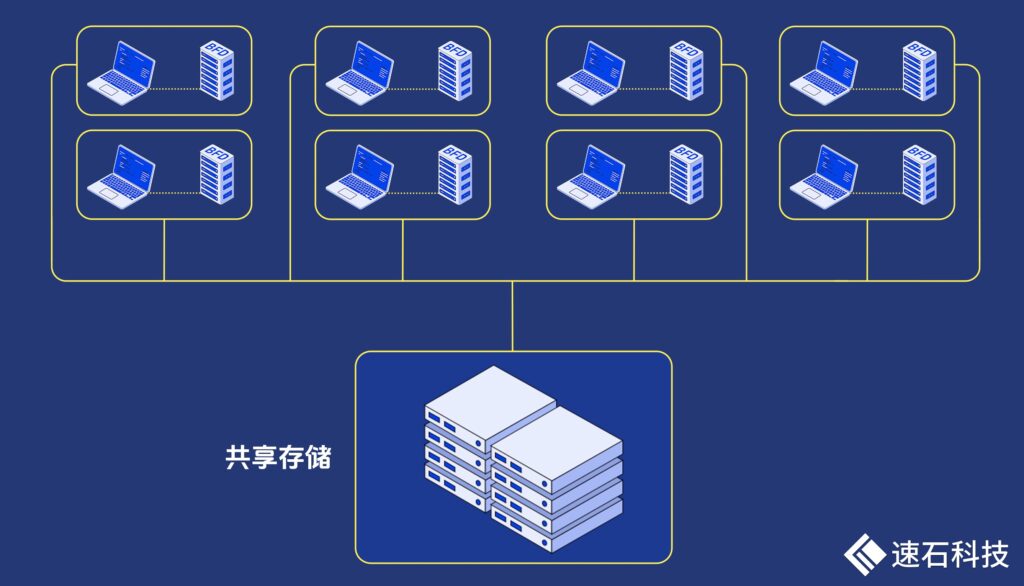
這帶來了兩大好處:
第一、磁盤空間換時間,計算速度更快
將高頻訪問的BFD數(shù)據(jù)庫放在本地磁盤上,I/O讀寫速度快,非常適合需要快速響應的數(shù)據(jù)。因為本地磁盤是與機器綁定的,如果不止一臺機器,這會導致本地磁盤存儲空間增加。
而其他對I/O讀寫速度要求不高的數(shù)據(jù)庫可以放在網(wǎng)絡共享存儲上,方便所有機器共享讀取和寫入,減少數(shù)據(jù)同步問題。
整體來說,用磁盤空間換取時間,讓I/O對計算的影響降到最低,顯著提升了AF2的運算效率。
第二、為未來可能的大規(guī)模并發(fā)計算掃清技術(shù)障礙
關(guān)于這一點,我們進入下一節(jié)。
04
大規(guī)模并發(fā)!
同時預測100+蛋白質(zhì)結(jié)構(gòu)
對用戶來說,不可能一次只預測1個蛋白質(zhì)結(jié)構(gòu)。
那么,如果要同時預測100+蛋白質(zhì)結(jié)構(gòu),怎么玩?
如果是以前,你不但需要搭好運行環(huán)境,準備好計算資源,然后一個一個預測,而且每一個還得手動走一遍完整的計算流程。這個過程一聽就十分漫長,而且容易出錯。
而現(xiàn)在——
已知一:我們有Workflow全流程自動化的能力,單個蛋白質(zhì)預測已經(jīng)是一個自動化的Workflow了;
已知二:我們解決了I/O瓶頸問題,也就是說,多臺機器對I/O讀寫瓶頸問題已經(jīng)解決。
100+蛋白質(zhì)結(jié)構(gòu)預測,又有什么難的?

現(xiàn)在,我們只需要再多做一步,同時運行有100+個不同輸入?yún)?shù)的Workflow,就行了。而完成這一步需要具備兩個條件:
一 、充分的CPU/GPU資源
我們調(diào)用10萬核CPU資源,使用AutoDock Vina幫用戶進行了2800萬量級的大規(guī)模分子對接,將運算效率提高2920倍:提速2920倍!用AutoDock Vina對接2800萬個分子
我們智能自動化調(diào)度云端GPU/CPU異構(gòu)資源,包括155個NVIDIA Tesla V100和部分CPU資源,將運算16008個Amber任務的耗時從單GPU的4個月縮短到20小時:155個GPU!多云場景下的Amber自由能計算
二 、調(diào)度器能力
這么多機器和任務,怎么適配,按什么策略使用最佳,怎么配置、啟動、關(guān)閉,提高整體資源利用率,最好還能自動化管理、輔助管理決策等等,甚至怎么DEBUG,這需要的可不止是一點點技術(shù)。
詳情可戳:國產(chǎn)調(diào)度器之光——Fsched到底有多能打?
到這里,這100+蛋白質(zhì)預測任務,就可以一次性跑完了。
05
V100 VS A100
關(guān)于GPU的一點選型建議
那么多GPU型號,你選哪個?
市面上的GPU型號不少,性能和價格差異也很大。
我們選取了3個蛋白質(zhì),分別使用V100和A100進行了一輪計算:

可以看到,對同一個蛋白質(zhì)進行結(jié)構(gòu)預測,A100用時約為V100的60-64%。
而目前的市場價,無論是小時租賃、包月預留還是裸卡買斷,A100至少是V100的2倍以上。
也就是說,A100是以2倍多的價格,去換取約三分之一的性能提升。
兩相比較,除非不差錢,我們推薦使用V100。
實證小結(jié)
1.AlphaFold2是一個系統(tǒng),涉及到很多數(shù)據(jù)庫和不同軟件,我們的Workflow全流程自動化,讓用戶可以隨心組合,輕松上手蛋白質(zhì)結(jié)構(gòu)預測;
2.我們用磁盤空間換時間的手段,既解決了TB級數(shù)據(jù)帶來的I/O瓶頸問題,也為大規(guī)模并發(fā)計算掃清了技術(shù)障礙;
3.fastone可支持多個AlphaFold2任務大規(guī)模自動并行;
4.GPU也需要選型,我們推薦V100。
本次生信實證系列Vol.15就到這里。
關(guān)于fastone云平臺在各種BIO應用上的表現(xiàn),可以點擊以下應用名稱查看
Vina│Amber│?MOE│?LeDock
速石科技新藥研發(fā)行業(yè)白皮書,可以戳下方查看:
新藥研發(fā)37問?│頂尖藥企AIDD調(diào)研
- END?-
我們有個一站式新藥研發(fā)平臺
集成行業(yè)應用與自編譯軟件
支持AlphaFold、RoseTTAFold等常用AI應用
可視化Workflow隨心創(chuàng)建、便捷分享
提供Zinc、Drugbank等開源/自有分子庫
CADD專家團隊全面支持掃碼
免費試用,送200元體驗金,入股不虧~

更多BIO電子書
歡迎掃碼關(guān)注小F(ID:iamfastone)獲取

你也許想了解具體的落地場景:
只做Best in Class的必揚醫(yī)藥說:選擇速石,是一條捷徑
王者帶飛LeDock!開箱即用&一鍵定位分子庫+全流程自動化3.5小時完成20萬分子對接
1分鐘告訴你用MOE模擬200000個分子要花多少錢
155個GPU!多云場景下的 Amber自由能計算
提速2920倍!用AutoDock Vina對接2800萬個分子
新藥研發(fā)平臺:
今日上新——FCP
專有D區(qū)震撼上市,高性價比的稀缺大機型誰不愛?
國產(chǎn)調(diào)度器之光——Fsched到底有多能打?
創(chuàng)新藥研發(fā)九死一生,CADD/AIDD是答案嗎?
全球44家頂尖藥企AI輔助藥研行動白皮書
近期重大事件:
速石科技完成龍芯、海光、超云兼容互認證,拓寬信創(chuàng)生態(tài)版圖
速石科技入駐粵港澳大灣區(qū)算力調(diào)度平臺,參與建設數(shù)算用一體化發(fā)展新范式
速石科技成NEXT PARK產(chǎn)業(yè)合伙人,共同打造全球領(lǐng)先的新興產(chǎn)業(yè)集群
速石科技出席ICCAD2023,新一代芯片研發(fā)平臺助力半導體企業(yè)縮短研發(fā)周期
速石科技與芯啟源開啟戰(zhàn)略合作,聯(lián)手打造軟硬件一體芯片研發(fā)云平臺







