
如果有一天,你有16萬個CPU,你要怎么用?
夢想還是要有的,萬一它實現了呢?
首先,你要有個調度器。
我們現在說的調度器,主要是基于HPC場景的集群任務調度系統,英文叫Cluster Scheduler、Job Scheduler等。
市面上主流調度器有四大流派:LSF/SGE/Slurm/PBS。
不同行業因為使用習慣和不同調度器對應用的支持力度不同,往往會有不同的偏好:比如高校和超算經常用Slurm,半導體公司最常用的是LSF和SGE,工業制造業可能用PBS更多一些。
調度器是干嘛的?
如果有一臺或者幾臺機器,專屬你所有,你可以抱著他們一直持續而緩慢地用下去,調度器是沒什么用武之地的。
那什么場景需要呢?資源緊張或者時間緊張的時候。
為啥緊張就需要呢?因為需要最大程度壓榨現有資源或時間的最大價值。
比如驗證跑個regression,如何做到幾萬個test case并行?
用1臺機器做分子對接和1000臺有什么區別?100000臺呢?
舉個例子。
這是上次那篇 15小時虛擬篩選10億分子,《Nature》+HMS驗證云端新藥研發未來 文章里哈佛大學醫學院用云端16萬個CPU來篩選10億種化合物,只用了15小時。
這是他們提供的超大規模計算集群上的工作流程圖:
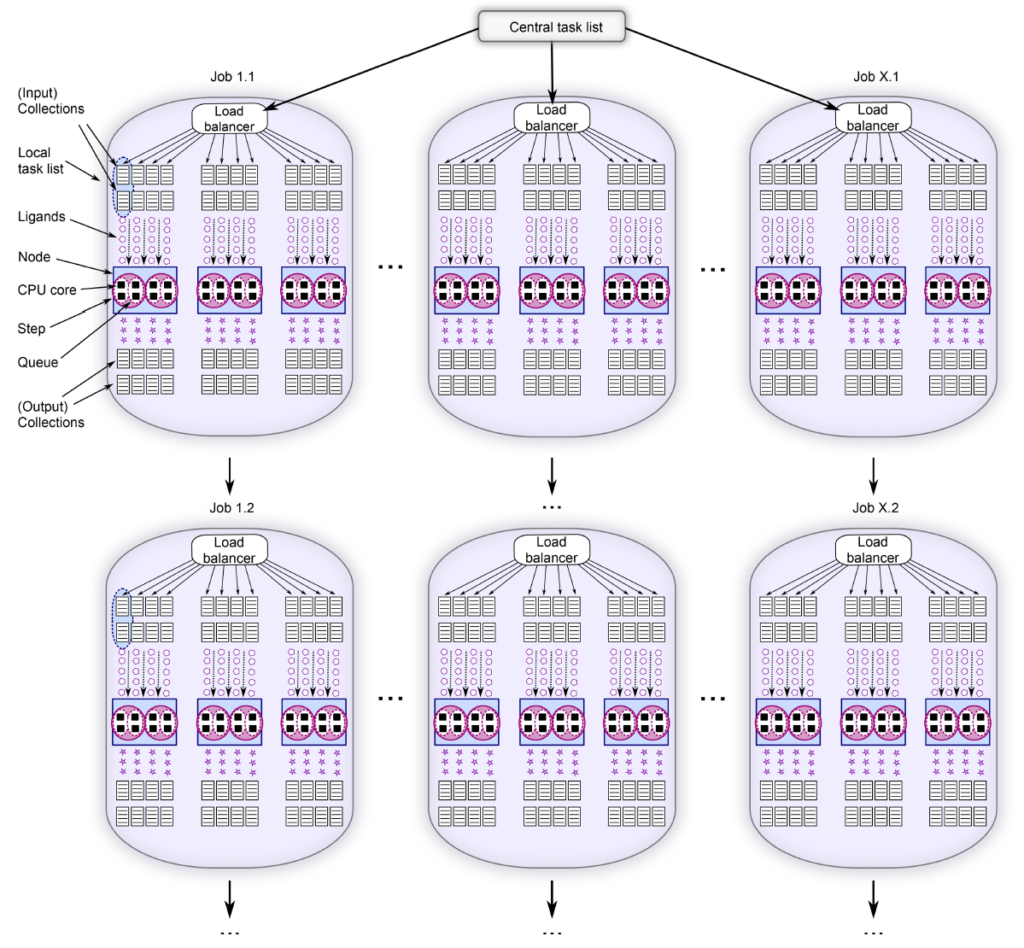
藍色框表示計算節點,其中包含CPU核數(藍色框內的黑色正方形),紫色小圓圈代表待處理的配體。整張圖代表整個計算集群,并行運行1.1到X.1個任務,任務1.1完成后會自動運行任務1.2,以此類推直到任務完成。
每個任務(包含多個子任務)使用3個計算節點,每個節點有8個CPU核。
假設我們有10億化合物需要篩選,面對16萬CPU,把流程圖里缺乏的時間維度考慮進來,我們可以多思考幾個問題:
- 16萬CPU,怎么順利一一配置,啟動,關閉?
- 怎么能讓集群整體資源利用率最高?跑更多任務?
- 能不能指定特定任務在某種類型計算節點上運行?
- 任務之間存在先后順序,能否確保特定任務一定先運行?
- 怎么統計和限制不同用戶的用量?
- 怎么監控每個節點的狀態和使用情況?
- 怎么降低集群的整體運行成本?避免浪費?
- 計算節點間網絡/數據傳輸怎么考慮?
- 如何應對云上集群資源高度動態的特性?空閑資源不足時怎么辦?
……
當然,有些事已經不屬于調度器的范疇了,這次我們不展開。
如果還不是特別明白,再打個比方。認真想像一下你是老板,手里有且只有100個打工人,你想想要怎么管理才能讓他們更好地為你工作??
好了,靈魂科普就到這里。
今天我們基于這幾家主流調度器:LSF/SGE/Slurm/PBS以及它們的不同演化版本進行了梳理和盤點,尤其是對云的支持方面劃了重點。
以下是正文。
LSF流派
Spectrum LSF、PlatformLSF、OpenLava
基于LSF(Load Sharing Facility)的調度器主要有Spectrum LSF、PlatformLSF、OpenLava三家。
早期的LSF是由Toronto大學開發的Utopia系統發展而來。
2007年,Platform Computing基于早期老版本的LSF開源了一個簡化版Platform Lava。
這個開源項目2011年中止了,被OpenLava接手。
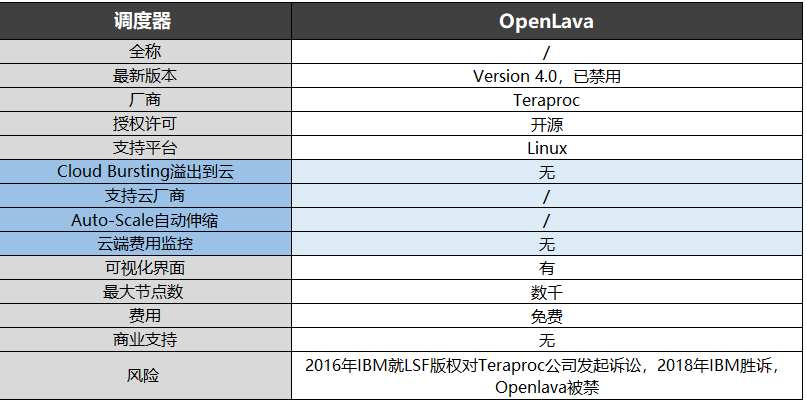
2011年,Platform員工David Bigagli基于Platform Lava的派生代碼創建了OpenLava 1.0。2014年,一些Platform的員工成立了Teraproc公司,為OpenLava提供開發和商業支持。2016年IBM就LSF版權對Teraproc公司發起訴訟,2018年IBM勝訴,OpenLava被禁用。
2011年,Platform Lava開源項目中止后。2012年1月,IBM收購了Platform Computing。Spectrum LSF就是IBM收購后推出的商用版本,目前更新到10.1.0,同時支持Linux和Windows,最大節點數超過6000,在國內提供商業支持。
Platform LSF是LSF的早期版本,與Spectrum LSF一樣屬于IBM,目前版本是9.1.3,目測已經停止更新以維護為主。
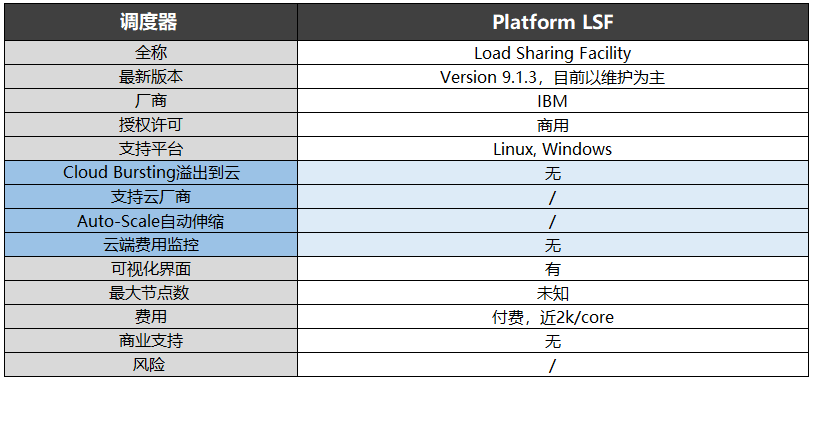
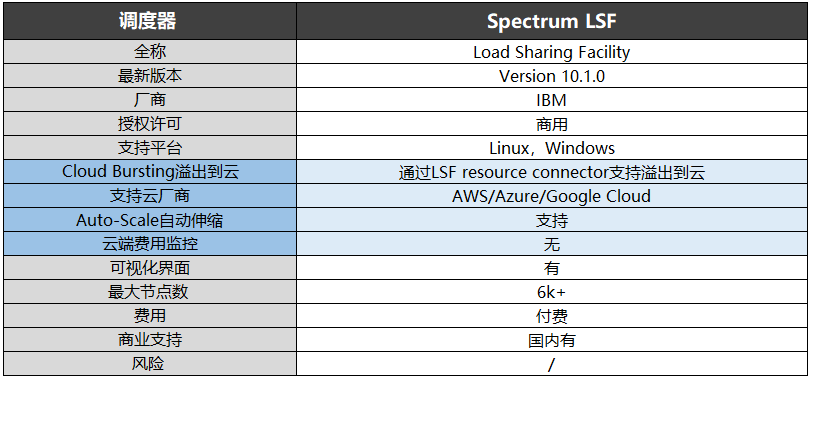
在這三個調度器中,僅有Spectrum LSF支持Auto-Scale集群自動伸縮功能,同時該調度器還可通過LSF resourceconnector實現溢出到云,支持云廠商包括AWS、Azure、Google Cloud。
SGE流派
UGE、SGE
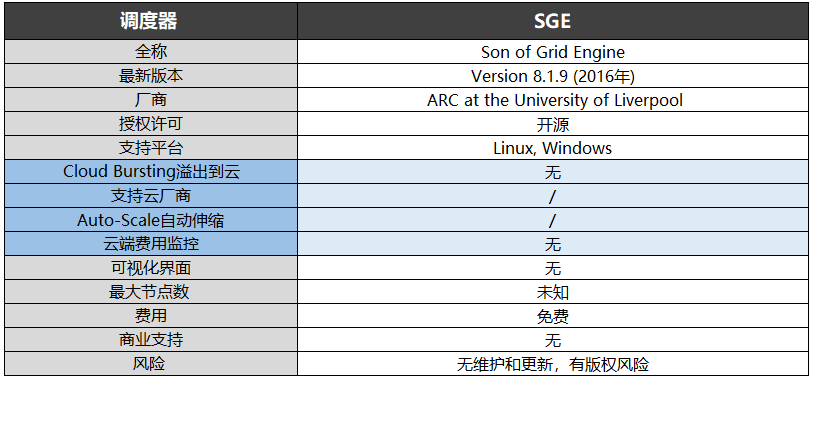
基于SGE(Sun Grid Engine)的調度器包括UGE(Univa Grid Engine)和SGE(Son of Grid Engine)。
1993年,Grid Engine作為商業軟件發布,先后使用了CODINE(Computing in Distributed Networked Environments)、GRD(Global Resource Director)作為名稱。1999年,第一次由Genias Software推出市場,然后被Gridware公司收購。直到2000年被SUN收購之后正式改名Sun Grid Engine,2001年發布開源版。
2010年被Oracle收購后改名Oracle Grid Engine,改成閉源版,不提供源代碼。原來開源項目的資料庫禁止用戶修改。
于是,Grid Engine社區開始開源版本的SGE(Son of Grid Engine)項目。該調度器最后一次更新為2016年的8.1.9,由于存在版權風險,SGE已長期無維護和更新。
2013年Univa收購了Oracle Grid Engine,成為唯一商業軟件UGE(Univa Grid Engine)提供商。UGE最新版本為8.6.15,同時支持Linux和Windows,國內暫無商業支持的相關信息。
2020年9月,Altair收購了Univa。
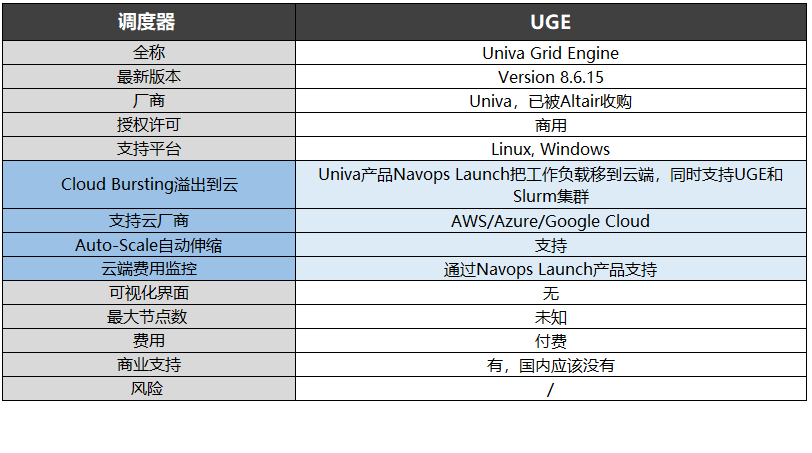
用戶可通過Univa產品Navops Launch把工作負載移到云端,同時支持UGE和Slurm集群。同時,Navops Launch支持AWS、Azure、Google Cloud等云廠商,并能進行云端費用監控以及Auto-Scale集群自動伸縮。
Slurm-四大流派里唯一純開源派
Slurm全稱為Simple Linux Utility for Resource Management,前期主要由勞倫斯利弗莫爾國家實驗室、SchedMD、Linux NetworX、Hewlett-Packard 和 Groupe Bull 負責開發,受到閉源軟件Quadrics RMS的啟發。
Slurm最新版本為20.02,目前由社區和SchedMD公司共同維護,保持開源和免費,由SchedMD公司提供商業支持,僅支持Linux系統,最大節點數量超過12萬。
Slurm擁有容錯率高、支持異構資源、高度可擴展等優點,每秒可提交超過1000個任務,且由于是開放框架,高度可配置,擁有超過100種插件,因此適用性相當強。
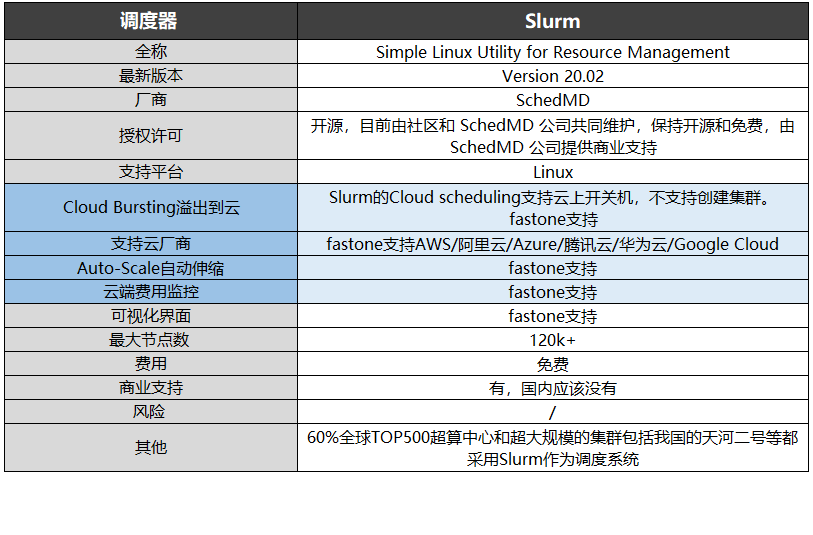
全球60%的TOP500超算中心和超大規模集群(包括我國的天河二號等)都采用Slurm作為調度系統。我們的TOP500就是用Slurm調度云上資源跑的。上榜啦~花費4小時5500美元,速石科技躋身全球超算TOP500
我們支持在Slurm上的集群自動伸縮和云端費用監控,并支持AWS、阿里云、Azure、騰訊云、華為云、Google Cloud等云廠商。
fastone的Auto-Scale功能可以自動監控用戶提交的任務數量和資源的需求,動態按需地開啟所需算力資源,在提升效率的同時有效降低成本。
EDA云實證Vol.1:從30天到17小時,如何讓HSPICE仿真效率提升42倍? 這篇主要看通過我們自動化部署和手動部署的差別。
CAE云實證Vol.2:從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
生信云實證Vol.3:提速2920倍!用AutoDockVina對接2800萬個分子 這篇主要看我們基于用戶不同的策略,跨區、跨類型自動為用戶調度云資源,如何以最快速度or最低成本完成計算任務。
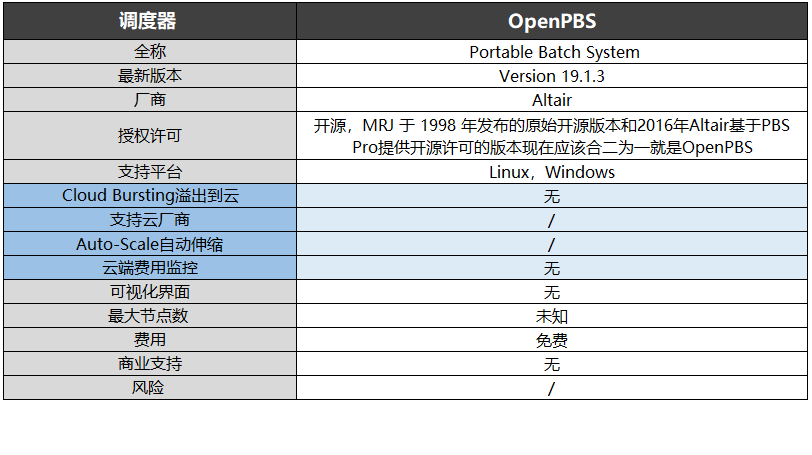
PBS流派
OpenPBS、PBS PRO、Moab/TORQUE
基于PBS(Portable Batch System)的調度器包括OpenPBS、PBS PRO、Moab/TORQUE。
PBS最初是由MRJ Technology Solutions于 1991 年 6 月開始為 NASA 所研發的作業調度系統,MRJ于 20 世紀90 年代末被 Veridian 收購。2003年,Altair收購了Veridian,獲得了PBS的技術和知識產權。
PBS Pro是Altair旗下PBS WORKS提供的商業版本,支持可視化界面,節點數超過50000個。
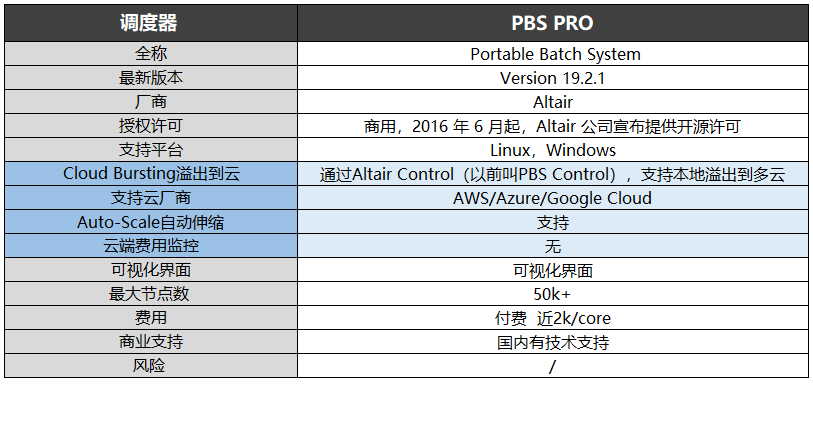
2016年Altair基于PBS Pro提供了開源許可版本,其與MRJ于1998年發布的原始開源版本兩者合二為一大致就是現在的OpenPBS。與Pro版本比,多了很多限制,但都支持Linux和Windows。
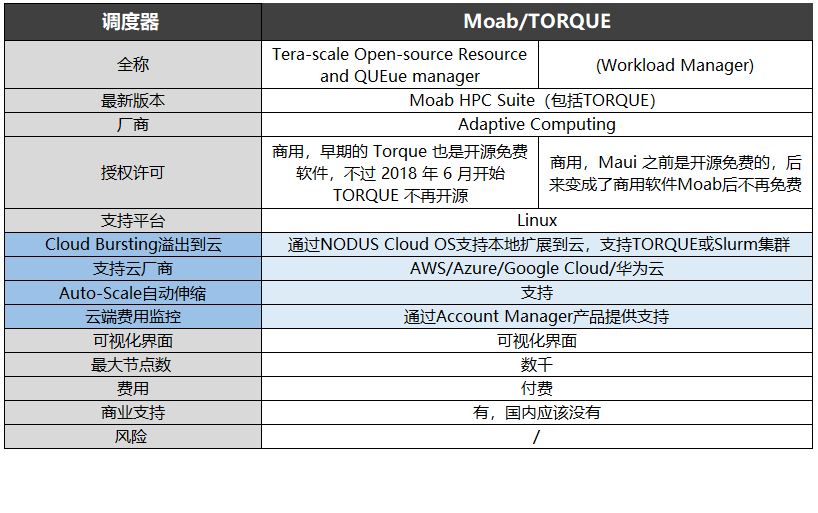
Moab/TORQUE合在一起是一個完整調度器的功能,現在屬于同一家公司Adaptive Computing。90年代中期由MHPCC的David Jackson開發的Maui,他后來創立了Adaptive Computing。
Moab是Adaptive Computing 公司(前身為 Cluster Resources 公司開發的Maui Cluster Scheduler)維護的 OpenPBS 分支,2003年發布。該項目最初是開源免費的,后來變成了商用軟件Moab后不再免費。
TORQUE(Terascale Open-source Resource and QUEue Manager)早期的 Torque 也是開源免費軟件,不過 2018 年 6 月開始 TORQUE 不再開源。
兩者均只支持Linux系統,提供可視化界面,擁有約數千個節點。
云服務方面,PBS Pro能通過Altair Control產品從本地溢出到多云和Auto-Scale集群自動伸縮,支持的云廠商包括AWS、Azure和Google Cloud。
Moab/TORQUE 則可通過 NODUSCloud OS 產品實現本地擴展到云,支持TORQUE 或 Slurm集群和自動伸縮,可支持的云廠商包括AWS、Azure、GoogleCloud 和華為云,并通過 Account Manager 產品實現云端費用監控。
我們整理了一張包含上述四大類共9種調度器在內的信息集成表,有興趣的可以文末掃碼添加小F微信(ID:imfastone),回復“調度器”獲取原始表單。
預告一下,在下一篇EDA云實證Vol.4中,我們在相同場景下使用不同調度器進行了云端驗證,敬請期待吧!
- END -
2分鐘自動開通,即刻獲得TOP500超級算力
點擊下圖立即體驗

2020年新版《六大云廠商資源價格對比工具包》
添加小F微信(ID: imfastone)獲取

你也許想了解具體的落地場景:
生信云實證Vol.3:提速2920倍!用AutoDock Vina對接2800萬個分子
CAE云實證Vol.2:從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
EDA云實證Vol.1:從30天到17小時,如何讓HSPICE仿真效率提升42倍?
15小時虛擬篩選10億分子,《Nature》+HMS驗證云端新藥研發未來
關于云端高性能計算平臺:
國內超算發展近40年,終于遇到了一個像樣的對手
幫助CXO解惑上云成本的迷思,看這篇就夠了
靈魂畫師,在線科普多云平臺/CMP云管平臺/中間件/虛擬化/容器是個啥
花費4小時5500美元,速石科技躋身全球超算TOP500






