

LLM大語言模型的定義
大語言模型(英文:Large Language Model,縮寫LLM),也稱大型語言模型,是一種人工智能模型,旨在理解和生成人類語言。它們在大量的文本數(shù)據(jù)上進行訓(xùn)練,可以執(zhí)行廣泛的任務(wù),包括文本總結(jié)、翻譯、情感分析等等。LLM的特點是規(guī)模龐大,包含數(shù)十億的參數(shù),幫助它們學習語言數(shù)據(jù)中的復(fù)雜模式。這些模型通常基于深度學習架構(gòu),如轉(zhuǎn)化器,這有助于它們在各種NLP任務(wù)上取得令人印象深刻的表現(xiàn)。
LLM到底有多大?
拿 GPT 來說, GPT 其實出現(xiàn)了好幾代,GPT 3 它有 45 個 Tb 的訓(xùn)練數(shù)據(jù),那么整個維基百科里面的數(shù)據(jù)只相當于他訓(xùn)練數(shù)據(jù)的 0. 6%。我們在這個訓(xùn)練的時候把這個東西稱作語料,就語言材料,這個語料的量是可以說是集中到我們?nèi)祟愃姓Z言文明的精華在里面,這是一個非常非常龐大的一個數(shù)據(jù)庫。
從量變到質(zhì)變
經(jīng)過這樣的一個量的學習之后,它產(chǎn)生的一些就是做 AI 的這些計算機學家們,他們沒有想到會有這種變化,無法合理解釋這一現(xiàn)象的產(chǎn)生即——當數(shù)據(jù)量超過某個臨界點時,模型實現(xiàn)了顯著的性能提升,并出現(xiàn)了小模型中不存在的能力,比如上下文學習(in-context learning)。
這也就催生了兩個事件:
- 各大AI巨頭提高訓(xùn)練參數(shù)量以期達到更好的效果
- 由于質(zhì)變原因的無法解釋帶來的AI安全性考量
LLM涌現(xiàn)的能力
- 上下文學習。GPT-3 正式引入了上下文學習能力:假設(shè)語言模型已經(jīng)提供了自然語言指令和多個任務(wù)描述,它可以通過完成輸入文本的詞序列來生成測試實例的預(yù)期輸出,而無需額外的訓(xùn)練或梯度更新。
- 指令遵循。通過對自然語言描述(即指令)格式化的多任務(wù)數(shù)據(jù)集的混合進行微調(diào),LLM 在微小的任務(wù)上表現(xiàn)良好,這些任務(wù)也以指令的形式所描述。這種能力下,指令調(diào)優(yōu)使 LLM 能夠在不使用顯式樣本的情況下通過理解任務(wù)指令來執(zhí)行新任務(wù),這可以大大提高泛化能力。
- 循序漸進的推理。對于小語言模型,通常很難解決涉及多個推理步驟的復(fù)雜任務(wù),例如數(shù)學學科單詞問題。同時,通過思維鏈推理策略,LLM 可以通過利用涉及中間推理步驟的 prompt 機制來解決此類任務(wù)得出最終答案。據(jù)推測,這種能力可能是通過代碼訓(xùn)練獲得的。
語言模型歷史
2017谷歌推出 transformer 模型,2018 年的時候谷歌提出了 Bert 的模型,然后到 GPT 2,從 340 兆到 10 億 、15 億,然后到 83 億,然后到 170 億,然后到 GPT3 1750 億的參數(shù)。
最早的是 2017 年出來的,就是我們所了解的那個GPT, GPT 名字里面有一個叫做transformer,就是這個 transformer 模型。它是 2017 年出現(xiàn)的,其實也很早,所以計算機領(lǐng)域來說, 2017 年可以歸結(jié)于上一個時代的產(chǎn)品。然后 2018 年第一代 GPT 出來,當時還不行,相對來說比較差,性能也不行,然后像一個玩具一樣。然后 2018 年谷歌又推出了一個新的模型,叫BERT,但是這些模型都是基于之前谷歌推出的這個 transformer 模型進行發(fā)展的。然后到了 2019 年, open AI 除了 GPT 2 也沒有什么特別,就是它沒有辦法來產(chǎn)生一個語言邏輯流暢通順的一段名詞,你一看就知道這是機器寫的。
但是到了 2020 年的5月, GPT 3 出來之后,其實就有了非常大的變化, GPT 3 的性能比 GPT 2 好很多,它的數(shù)參數(shù)的數(shù)量級大概是 GPT 2- 10 倍以上。
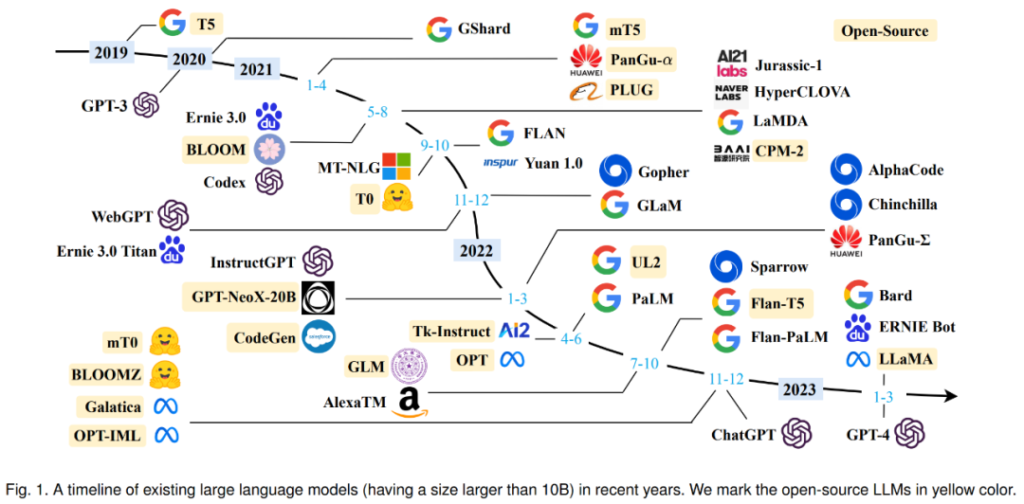
LLM的訓(xùn)練方式
訓(xùn)練語言模型需要向其提供大量的文本數(shù)據(jù),模型利用這些數(shù)據(jù)來學習人類語言的結(jié)構(gòu)、語法和語義。這個過程通常是通過無監(jiān)督學習完成的,使用一種叫做自我監(jiān)督學習的技術(shù)。在自我監(jiān)督學習中,模型通過預(yù)測序列中的下一個詞或標記,為輸入的數(shù)據(jù)生成自己的標簽,并給出之前的詞。
訓(xùn)練過程包括兩個主要步驟:預(yù)訓(xùn)練(pre-training)和微調(diào)(fine-tuning):
- 在預(yù)訓(xùn)練階段,模型從一個巨大的、多樣化的數(shù)據(jù)集中學習,通常包含來自不同來源的數(shù)十億詞匯,如網(wǎng)站、書籍和文章。這個階段允許模型學習一般的語言模式和表征。
- 在微調(diào)階段,模型在與目標任務(wù)或領(lǐng)域相關(guān)的更具體、更小的數(shù)據(jù)集上進一步訓(xùn)練。這有助于模型微調(diào)其理解,并適應(yīng)任務(wù)的特殊要求。
常見的大語言模型
GPT-3(OpenAI): Generative Pre-trained Transformer 3(GPT-3)是最著名的LLM之一,擁有1750億個參數(shù)。該模型在文本生成、翻譯和其他任務(wù)中表現(xiàn)出顯著的性能,在全球范圍內(nèi)引起了熱烈的反響,目前OpenAI已經(jīng)迭代到了GPT-4版本
BERT(谷歌):Bidirectional Encoder Representations from Transformers(BERT)是另一個流行的LLM,對NLP研究產(chǎn)生了重大影響。該模型使用雙向方法從一個詞的左右兩邊捕捉上下文,使得各種任務(wù)的性能提高,如情感分析和命名實體識別。
T5(谷歌): 文本到文本轉(zhuǎn)換器(T5)是一個LLM,該模型將所有的NLP任務(wù)限定為文本到文本問題,簡化了模型適應(yīng)不同任務(wù)的過程。T5在總結(jié)、翻譯和問題回答等任務(wù)中表現(xiàn)出強大的性能。
ERNIE 3.0 文心大模型(百度):百度推出的大語言模型ERNIE 3.0首次在百億級和千億級預(yù)訓(xùn)練模型中引入大規(guī)模知識圖譜,提出了海量無監(jiān)督文本與大規(guī)模知識圖譜的平行預(yù)訓(xùn)練方法。
速石科技AI應(yīng)用
AI應(yīng)用落地是所有研發(fā)環(huán)節(jié)中最后一環(huán),也是最重要的一環(huán)。在AIGC應(yīng)用百花齊放的這波浪潮中,速石科技作為MLOps平臺的提供方,同時也是其使用方。
速石科技已經(jīng)發(fā)布一款行業(yè)知識庫聊天應(yīng)用Megrez,這款聊天應(yīng)用面向企業(yè)客戶提供大語言模型的私有化部署能力,解決了許多企業(yè)用戶關(guān)注的數(shù)據(jù)安全問題,它也允許用戶自定義行業(yè)知識庫,實現(xiàn)領(lǐng)域知識的問答。
更多可查看:速石科技應(yīng)邀出席2023世界人工智能大會,AI研發(fā)平臺引人矚目
本文轉(zhuǎn)載:https://zhuanlan.zhihu.com/p/622518771
- END -
我們有個AI研發(fā)云平臺
集成多種AI應(yīng)用,大量任務(wù)多節(jié)點并行
應(yīng)對短時間爆發(fā)性需求,連網(wǎng)即用
跑任務(wù)快,原來幾個月甚至幾年,現(xiàn)在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創(chuàng)建集群
掃碼免費試用,送200元體驗金,入股不虧~

更多電子書歡迎掃碼關(guān)注小F(ID:iamfastone)獲取
你也許想了解具體的落地場景:
王者帶飛LeDock!開箱即用&一鍵定位分子庫+全流程自動化,3.5小時完成20萬分子對接
這樣跑COMSOL,是不是就可以發(fā)Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規(guī)模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務(wù)背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發(fā)性Fluent仿真計算縮短到4天之內(nèi)?
5000核大規(guī)模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關(guān)于為應(yīng)用定義的云平臺:
當仿真外包成為過氣網(wǎng)紅后…
和28家業(yè)界大佬排排坐是一種怎樣的體驗?
這一屆科研計算人趕DDL紅寶書:學生篇
楊洋組織的“太空營救”中, 那2小時到底發(fā)生了什么?
一次搞懂速石科技三大產(chǎn)品:FCC、FCC-E、FCP
Ansys最新CAE調(diào)研報告找到阻礙仿真效率提升的“元兇”
國內(nèi)超算發(fā)展近40年,終于遇到了一個像樣的對手
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費4小時5500美元,速石科技躋身全球超算TOP500







